Over the past few months we’ve seen a growing stream of calls from frustrated customers seeking ways to improve performance when integrating Deltek Cobra 5 with Primavera P6. In part, the increase seems to be related to organizations switching away from Cobra 4.7 to Cobra 5, a move prompted by Microsoft ending support for Windows XP. With support for Windows XP scheduled to end on April 8, 2014, many primes and sub-contractors are migrating over to Windows 7.
The general issue is that when connecting to a large Primavera P6 database integration with Cobra 5 is proving much slower than with its 4.7 predecessor. We’ve had reports of integration processes taking over two hours to complete, with application server CPUs being tapped out at 100% throughout the process.
This article looks at some ideas to help speed up integration, many of which we’d had some success with. However there are still many unanswered questions about this problem and affected customers are looking to Deltek for answers. We’ll be keeping a close eye on this issue and keeping you all posted as we get news of progress.
In the meantime…
…What’s your Experience?
If you’ve been experiencing any such performance problems with P6 integration, we’d really like to hear from you. We’d like to gather examples from the Cobra user community and then share the aggregate of findings with all the respondents and Deltek. Your feedback could be invaluable in helping us all get to the nub of this issue. We’d like to know:
- The version of Primavera P6 you’re integrating with
- The database it’s installed on (Oracle or SQL Server)
- The Cobra version you’re using
- A general description of your experiences
- Any solutions that you or Deltek have come up with that helped speed up the process
Please email your comments to this address [email protected]
The Nature of the Issue
Part of the problem is that Primavera P6 databases tend to become very large, which is the nature of enterprise systems in general. It is also their nature to become cluttered when so many users are all sharing the same environment. Every backup copy of a project, every baseline, every inactive, planned or what-if project gets listed in the database project tables, right alongside the active projects. Adding to all this is the need to load daily time-phased data for baseline integration of projects that often span multiple years: so you can imagine the enormous arrays of data that need to be processed during integration.
Now, Primavera P6 itself rarely suffers too much from these volume issues because it is coded efficiently to its own enterprise database design. For example, it uses summary tables to keep high-level project data on the screen and only loads the larger volumes of project data when a project is opened for editing. It also calculates a lot of its data in memory only when the project is open, so much of the data values you see on the screen are nowhere to be found in the database tables.
When third-party tools connect to the P6 databases however, they do so via the constraints of an API. Unlike a simple ODBC connection, the P6 Integration API can provide some of the calculated data that you would only otherwise see in the application’s interface. It is in effect providing a subset of the product’s functionality without the need to open the main application. However it’s another process overhead that the third-party tool is dealing with. Therefore any inefficiency in either the API or the third-party code will exaggerate performance problems.
Mitigation Ideas
The following is our attempt to provide some ideas that may help you speed up your integration times.
Using the Primavera P6 Integration API
Performance is faster if you’re not using the Primavera P6 Integration API.
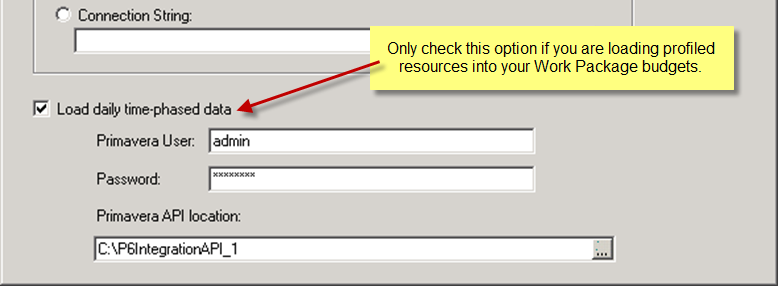
Unless your Integrated Master Schedule in Primavera P6 contains profiled resource assignments, you don’t need to use the P6 Integration API as part of your Connection configuration. The Primavera P6 Integration API is only used by the Integration Wizard to provide daily time-phased data. Its use therefore adds a considerable overhead to the integration process.

Also, if your periodic update cycle only requires status updates from the IMS, and not baseline changes, again you do not need to include the P6 Integration API in your connection; just connect using the ODBC driver and don’t check the “Load daily time-phased data” option in the Connection Selection dialog of the Integration Wizard.
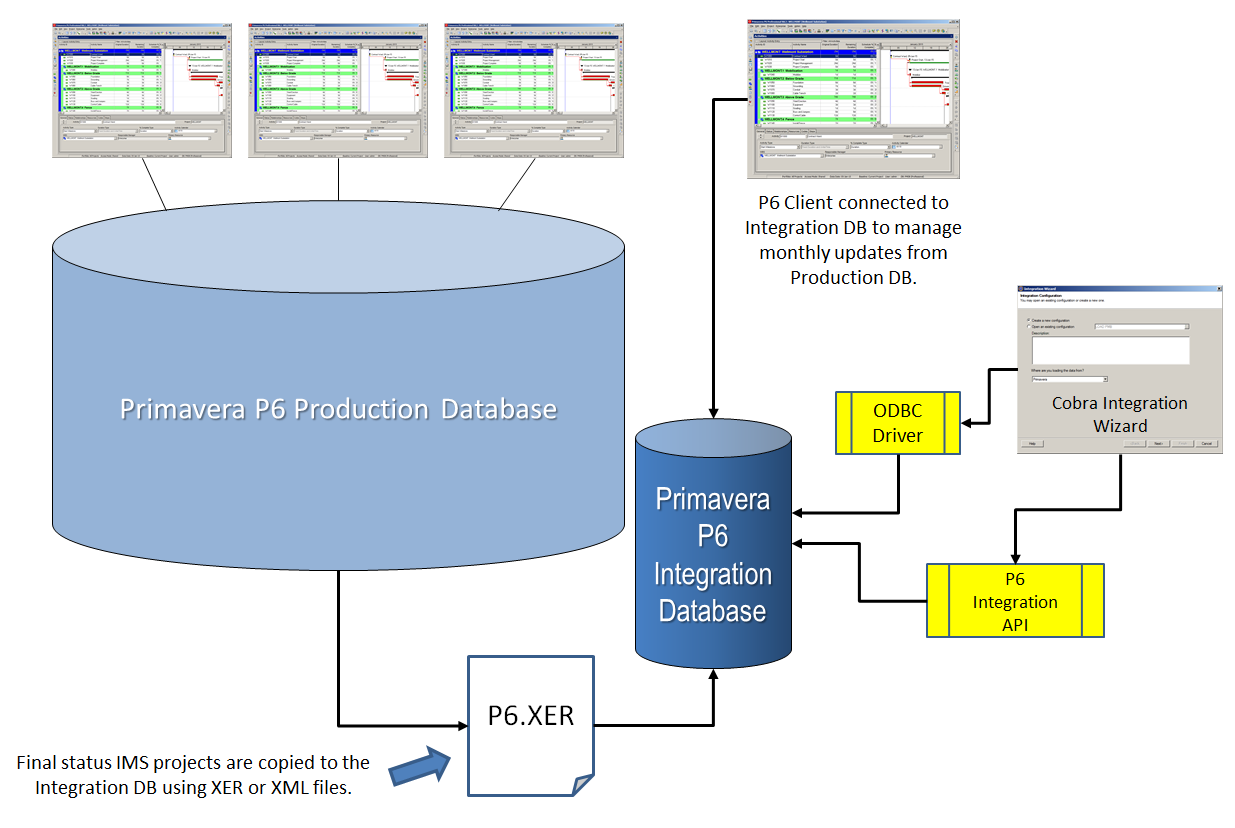
A Lean P6 Integration Database
Does your Primavera P6 Database contain unnecessary clutter such as old projects, unused interim baselines, non-integration projects, myriad backup copies of current projects?
If your EVM IMS projects are sharing a large Primavera P6 database that for whatever reason cannot be streamlined or archived, it might be a good idea to create a new P6 database instance used specifically for integrations. This Integration database would contain only one copy of each IMS project, which is overwritten each period with the final updated IMS that has been copied over from the production database using the XER or Primavera XML export formats.
Point the P6 integration API and ODBC drivers at this Integration database and do all your updates from there. This would guarantee the leanest possible database is being used by the Cobra Integration Wizard and should help significantly reduce the overall integration speeds.
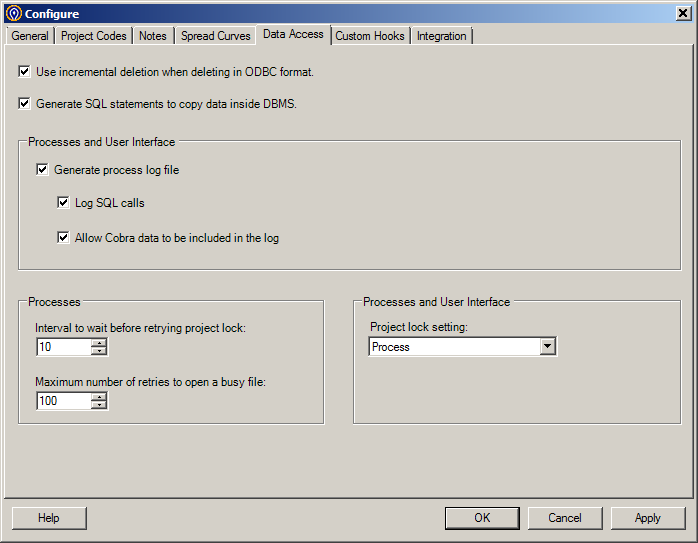
Process Logs
Process logs can also slow down the integration process. Check your configuration dialog to see if any of the process log settings are active.
Database Optimization
Both Microsoft SQL Server and Oracle databases provide methods for optimizing the performance. While we will not attempt to go into detail here, some of the main areas for potentially optimizing database performance include logical database design, index design, query design and application design. While most of these are out of our hands as far as database, query and application design go, we have had reports of performance improvements achieved by proper indexing of the database. So we recommend having your DB Administrator’s check into the status of indexing on both the Primavera P6 and Deltek Cobra databases.
ODBC Settings
In response to this article, Deltek’s Kathy Boatwright also pointed out: “If you are using Oracle, make sure the ‘Bind NUMBER As FLOAT’ setting on the Cobra5DSN ODBC connection is selected.”. She went on to say: “This prevents performance issues with Primavera when Cobra executes certain ‘select’ statements against the Primavera database. Note that this setting does not affect performance where Cobra calls the Primavera API directly. The ‘Bind NUMBER As FLOAT’ option is applicable to the Oracle 10.2 ODBC drivers and later”.
Many thanks for the additional details Kathy, we always appreciate your support.
Summary
We understand that these ideas may not be practical or even possible in some Cobra/Primavera P6 deployments. We’ve had some success with some of them, but they are at best a band-aid. We also can’t point the finger specifically at Deltek or Oracle Primavera as being the cause of the problem as we have no way to know if the inefficiencies exist in the Integration API code, Integration Wizard code or a little of both. All we can do at this point is try to reduce the burden on the systems we are attempting to integrate with though streamlining, archiving and optimizing.
Integration is such a critical part of the Deltek Cobra tool-set, and the Integration Wizard sets Cobra apart from all its competing tools so far as flexibility and ease of use are concerned. Addressing these performance issues when dealing with larger production databases, would continue to ensure that the combination of Primavera P6 and Deltek Cobra is the system to beat for your integrated EVMS solution.
To read more Deltek Cobra articles click here