 Deltek’s Acumen Risk analysis settings offer many options for the scheduler. If you are new to all this, you might find the defaults are a good place to start, but it is good to become aware of each setting’s effect.
Deltek’s Acumen Risk analysis settings offer many options for the scheduler. If you are new to all this, you might find the defaults are a good place to start, but it is good to become aware of each setting’s effect.
The Monte Carlo analysis comes with its own set of idiosyncrasies that, perhaps, is from its attempt to run the project hundreds and even thousands of times to predict the most probable schedule outcome. A standard Monte Carlo analysis in Deltek Acumen Risk, therefore, has numerous settings to accommodate these peculiarities, and to adjust the analysis depending on each individual schedule of differing size and correlations.
Further, multiple analysis scenarios can be generated using the Acumen Risk analysis settings. It is important for schedulers to have an awareness of these settings for the most realistic, accurate, and robust risk analysis of the schedule.
This article takes a walking tour through the Deltek Acumen Run Risk Analysis command settings to make schedulers at least cognizant of each setting.
Figure 1 displays the default settings of the Run Risk Analysis drop-down menu for a schedule risk model.
 Figure 1
Figure 1
As you can see in Figure 1, the Run Risk Analysis drop-down menu is rather lengthy; it has quite a few settings that require attention or a least some degree of understanding. I therefore grouped the run risk analysis drop-down menu in separate figures to shorten their length, and to facilitate discussion.
What follows are figures and discussion on each section of this Run Risk Analysis settings drop-down menu, along with other relevant figures.
Simulation
Well, the first stop on our walking tour is simulation, Figure 2, which concerns the accuracy and required length of time for the risk analysis.
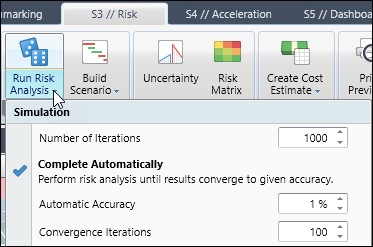 Figure 2
Figure 2
Most users opt to specify the risk analysis accuracy by the number of iterations, which is the default. Typically, users would run the analysis for the default 1000 iterations and note the results. Then they would double the number of iterations and see how close the second run’s results came to the first analysis. When the discrepancy between runs is minimal, you know you have included enough iterations in the Monte Carlo analysis.
The complete automatically option, provides high risk analysis accuracy for the lowest possible number of iterations. (Note that complete automatically is not selected in Figure 2, as the check mark does not have a box around it).
The complete automatically performs the risk analysis until either 1) results converge to a given accuracy or 2) the number iterations specified in the number of iterations field is reached. So, choose complete automatically and select a suitable percentage accuracy for the risk analysis. Acumen runs iterations until this accuracy is achieved.
Also, specify the convergence iterations, i.e. number of iterations over which the accuracy must be met. For Example, if convergence iterations option is set to 100 and automatic accuracy is fixed at 1% the risk analysis continues until the mean for the last 100 iterations is within 1% of each other.
The default settings for complete automatically are automatic accuracy 1% and convergence iterations 100. These default settings were arrived at using good basic statistics. It is important to be aware though that these complete automatically results are calculated at the mean. So, if you want results at a confidence level probability of 50% (P50), the mean, then complete automatically is a good option. It provides accuracy at a minimum number of iterations.
However, if you for example want a schedule completion date at a confidence level of P80 or P90 complete automatically is not the best option. This is because P80 and P90 are on the tail end of the probability distribution curve, where there is not enough sampling to produce accurate results. In most situations you are better served to use the simulation number of iterations approach, which, again, is the default setting in risk analysis.
Scenarios
Deltek Acumen has four separate scenarios that can be investigated, Figure 3.
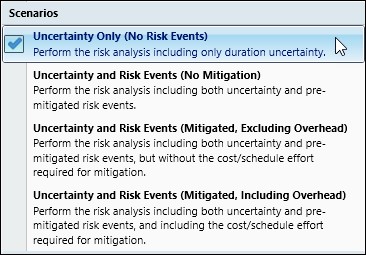 Figure 3
Figure 3
To consider only duration and/or cost uncertainty you want to set the scenario to ‘uncertainty only (no risk events)’. The probability and impact of schedule and/or cost risk events are included for the ‘uncertainty and risk events (no mitigation)’ setting. When ‘uncertainty and risk events (mitigated, excluding overhead)’ is set the analysis accounts for uncertainty and risk events in their mitigated state, but ignores the schedule and/or cost overhead to achieve this mitigation. Last set the analysis to ‘uncertainty and risk events (mitigate, including overhead)’ to add the mitigation effort’s schedule and cost expense to the analysis.
Some schedulers prefer keeping the duration and cost of mitigation separate from the risk tool. Their reasoning is the time and money for a mitigation effort does not normally add much to the overall schedule, so keeping it separate makes for a more robust mitigation proposal to stakeholders. If stakeholders do accept the mitigation proposal then the scheduler should go back and update the work and cost of mitigation in the schedule, respectively.
Sometimes the mitigation effort requires the insertion of additional activities and associated relationships. If this is your situation you are better served not including overhead in your scenario or run risk analysis settings. Instead, make the necessary changes including insertion of activities, relationships, and cost then run the risk analysis on the updated scope to find the result of your mitigation effort.
Interaction
Interaction, Figure 4, concerns the speed of the analysis weighted against the ability to view results for each iteration.
 Figure 4
Figure 4
For the fastest Monte Carlo analysis set the interaction to Automatic. In the Automatic interaction setting the screen displays a progress bar, but no results. The interactive setting provides real-time screen updates of results during the analysis. But you must be focused and fast to observe the results as they display on the screen only a quick moment for each iteration before disappearing from site.
If you want to pause and step through each iteration, then set the option to Diagnose. Figure 5 displays a screen capture of the Diagnose option that steps through each iteration.
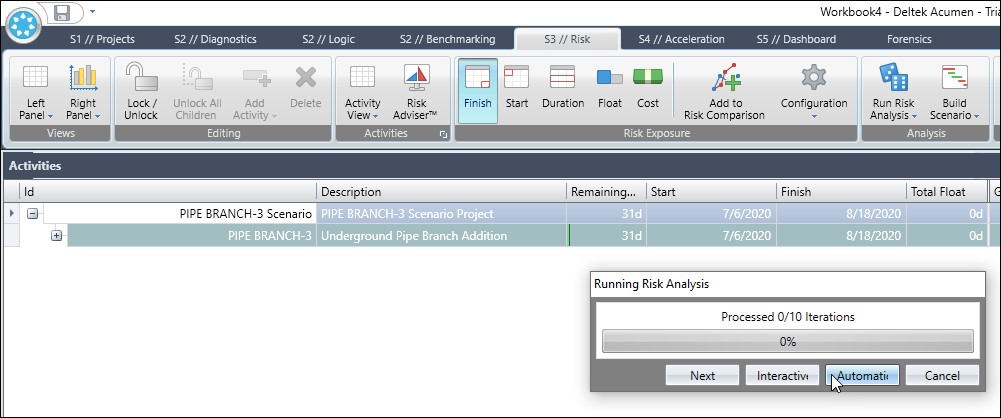 Figure 5
Figure 5
(Note the start and finish column results, Figure 5.) In Diagnose you must manually click next to proceed to the next iteration. If you begin Diagnose and want to revert to Automatic, then click the automatic button, Figure 5, to automatically run risk analysis iterations and view the values changing during execution.
Repeatability
To have repeatable risk analyses that calculates the exact same results each time use the fixed seed option, Figure 6, which is the default.
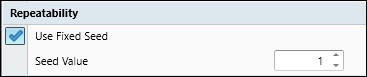 Figure 6
Figure 6
The use fixed seed option sets the Monte Carlo analysis to use the same group of random numbers for each analysis. The seed value corresponds to the group of random numbers that are used for the risk analysis. Repeatable results are achieved when use fixed seed is set and the seed value is the same. If the seed value is changed, the analysis runs using a different set of random numbers, and, therefore, computes different results. So, use fixed seed and the same seed value to ensure consistency between risk analysis runs, and for comparison of results with another scheduler using the same tool.
Activity Correlation
‘Use correlation to link activities’, Figure 7, correlates uncertainty outcomes between activities previously set up using the correlate command.
 Figure 7
Figure 7
Use activity-to-activity correlation when you believe you have causation. This causation is where the outcome of a predecessor activity relates directly to the outcome of a successor activity. The problem is that sometimes this causation is not realized in results when one predecessor activity’s extended duration is cancelled out by the successor activity’s shortened duration.
Activity correlation prevents this cancellation by breaking up randomness of the sampling from the probability distribution triangles. So, if you sample from the upper end of the probability distribution triangle for a predecessor 10-day task, correlation has you sample from the upper end of the triangle for the successor 18-day task, Figure 8.
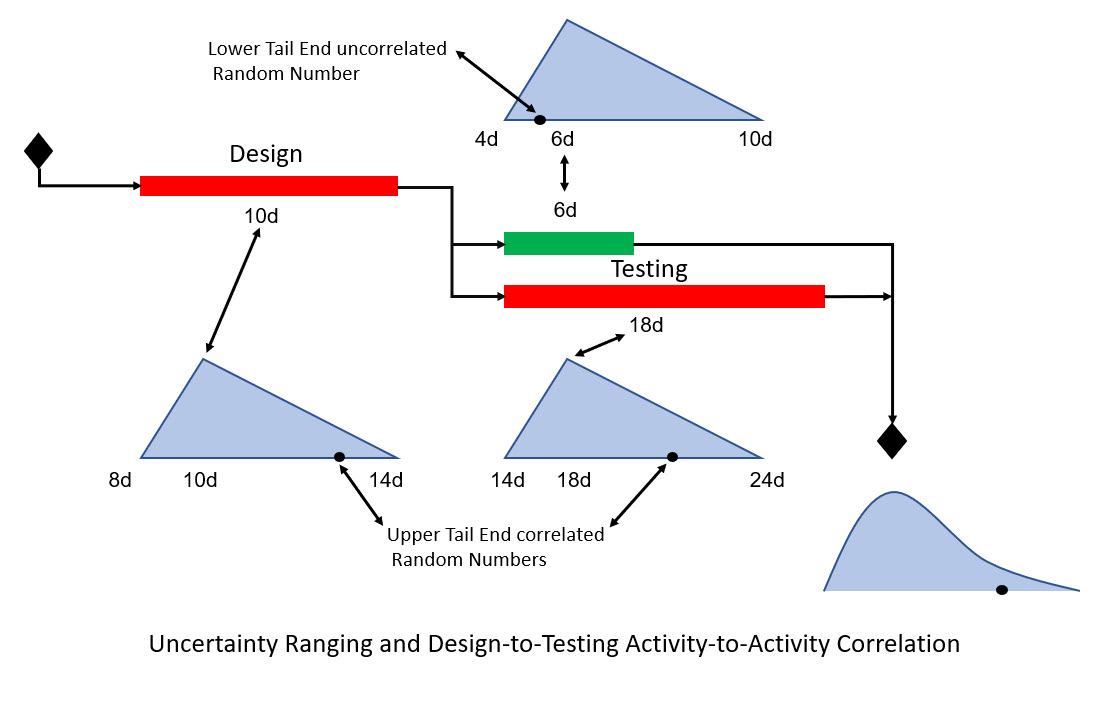 Figure 8
Figure 8
The successor takes its cue of where to sample from the probability distribution triangle of the predecessor based on where the predecessor random number is sampled. (Note that Acumen has normal and uniform probability distribution curves in addition to triangle. Triangle is the default and recommended approach for its combined efficiency and accuracy advantage.
A good example of applying this correlation is scheduling a new vendor. You want to make sure how the new vendor performs early on, either early or late, is correlated to successive activities. So, if your new vendor’s work progress tends toward the upper tail-end of the probability distribution triangle early on you want to continue this upper tail-end pattern for successive correlated activities. Another example is supplier performance. If a supplier delivers an item late, other scheduled deliveries from this supplier, most likely, will be late.
Finally, if technical problems or complexity delay design it is likely that implementation will delay due to unplanned required additional testing, again, Figure 8. So, a delayed design correlates to a delayed testing/implementation. Note in Figure 8 that both Design and Testing random number samplings come from the upper tail end of the probability distribution triangle. Of course, another possible way to handle technical risk is by inserting a risk event.
Let us demonstrate the process of inserting correlation between two activities. In Figure 9, we are in the Deltek Acumen S3 // Risk tab and viewing the activity table of an underground piping project. Note the correlation column, Figure 9.
 Figure 9
Figure 9
In this schedule we want to define correlation between the PIPE1050 ‘backhoe excavation’ activity and the PIPE1230 ‘install backfill & compact’ activity. This is because the same subcontractor is performing both the excavation and backfill efforts. We expect the subcontractor’s performance early/late during excavation will forecast their performance early/late during the backfill. In Figure 10 we click on the correlation button for ‘backhoe excavation’.
 Figure 10
Figure 10
In the correlation dialog, Figure 11, we enter backfill in the pink search field, and ‘install backfill & compact’ appears in the available activities list.
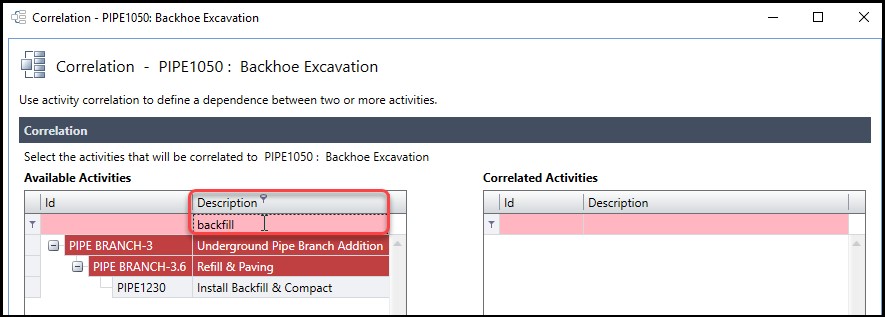 Figure 11
Figure 11
In Figure 12 we click the center arrow to move ‘install backfill & compact’ to the list of correlated activities.
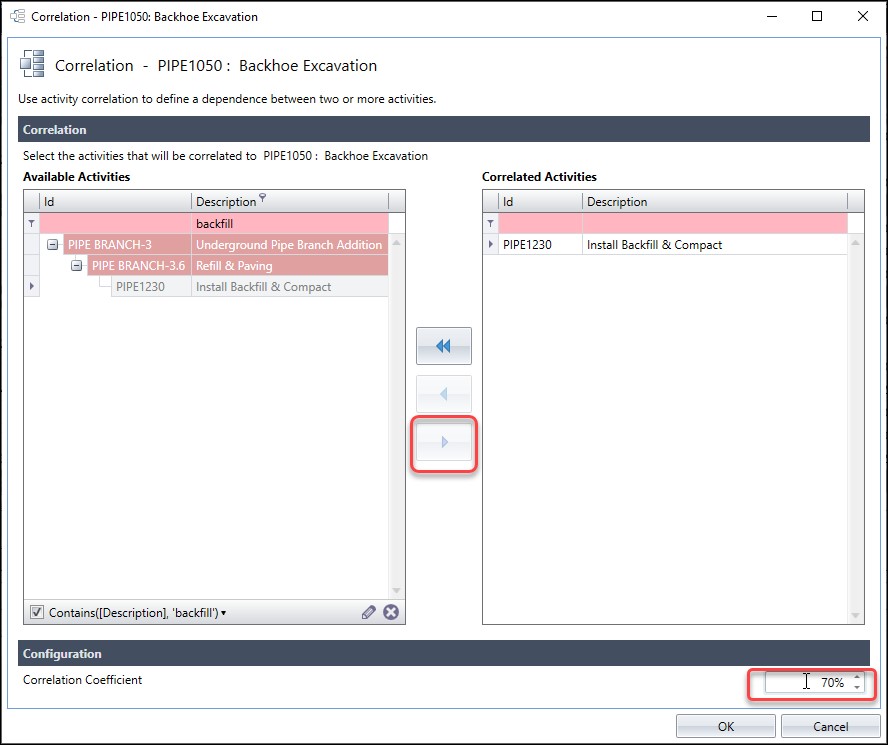 Figure 12
Figure 12
Then in the configuration section down below in the correlation dialog, Figure 12, we set the correlation coefficient to 70%. If the causation between activities is strong then, as a rule of thumb, we use 70% as the correlation coefficient. Finally, we hoover the mouse over the ‘backhoe excavation’ correlation button, Figure 13, to confirm that ‘backhoe excavation’ is correlated with ‘install backfill & compact’ at a 70% correlation coefficient.
 Figure 13
Figure 13
So, these two activities are now yoked or slaved together. When the random number value for ‘backhoe excavation’ is in the upper tail end of the probability distribution triangle then the random number value for ‘backfill & compact’ will be in the upper tail end.
Hierarchical Risk Models
The random number generator tends to produce values towards the middle of the distribution curve. To overcome the effects of this tendency, turn on ‘use correlation to overcome the central limit theorem’ (CLT). To clarify, CLT theorem states when you have large amounts of random numbers combined the following results:
- The random value outputs cluster in the middle
- The range min/max is narrower than reality
To demonstrate we have two schedules: (1) a 1 activity 100-day schedule with probability distribution triangle values 90/100/110d, (2) a 10-activity 100-day schedule with series connected activities in Finish-to-Start (FS) relationships and probability distribution triangle values for each activity 9/10/11d.
We ran the 1-activity schedule for Uncertainty Only (No Risk Events). Then we ran the 10-activity schedule for Uncertainty Only (No Risk Events) with no CLT correlation, 80% CLT correlation, 98% CLT correlation, and 100% CLT correlation. Results appear as follows in Figure 14.
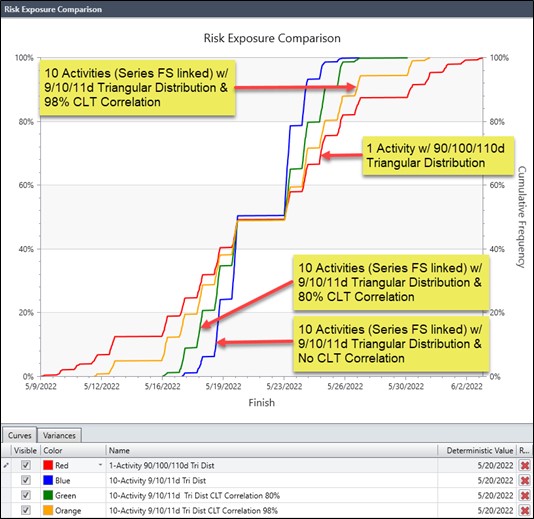 Figure 14
Figure 14
As displayed in Figure 14, the 10-activity 100-day schedule extreme values are less, i.e. the max/min are narrower than the 1-activity 100-day schedule. The 10-activity schedule did not come close to matching the 1-activity schedule until the 10-activity schedule CLT correlation coefficient was above 90%. When the 10-activity schedule CLT correlation coefficient was 100% the two schedules matched their uncertainty only results.
Let us demonstrate using the CLT for a cost risk model. In our cost risk model, Figure 15, we go to the CLT column and choose the top-level Work Breakdown Structure (WBS) element to activate CLT for all activities in the schedule.
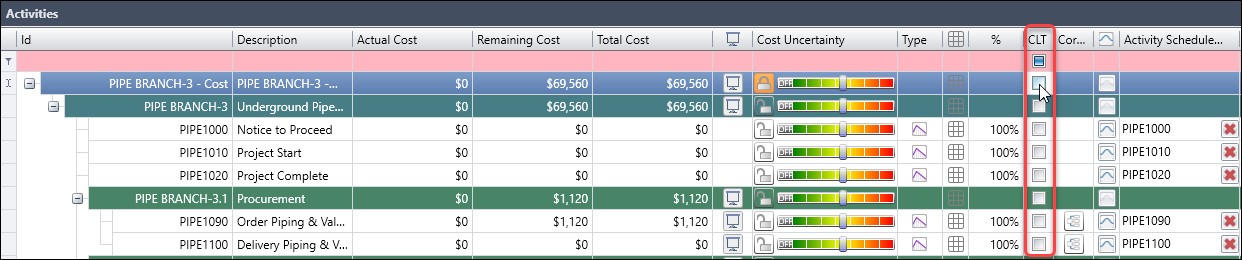 Figure 15
Figure 15
Figure 16 displays our cost risk model that has the CLT column activated.
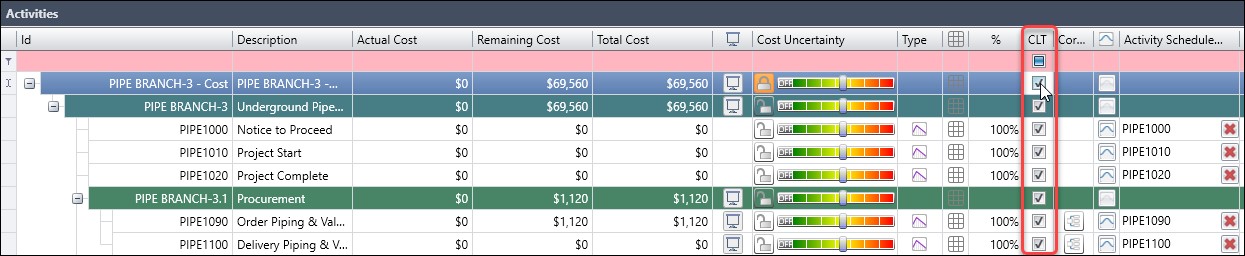 Figure 16
Figure 16
Finally, in Figure 17, we check to confirm ‘use correlation to overcome the central limit theorem’ is on and set the correlation coefficient to 100%, as per our study results.
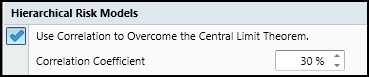 Figure 17
Figure 17
Cost/Schedule Integration
Finally, the cost/schedule integration option is the last setting on our walking tour. The cost/schedule integration risk analysis setting is only active for cost models. When running a cost model with schedule overlay set this option on, Figure 18, to include the impact of schedule delays on cost.
![]() Figure 18
Figure 18
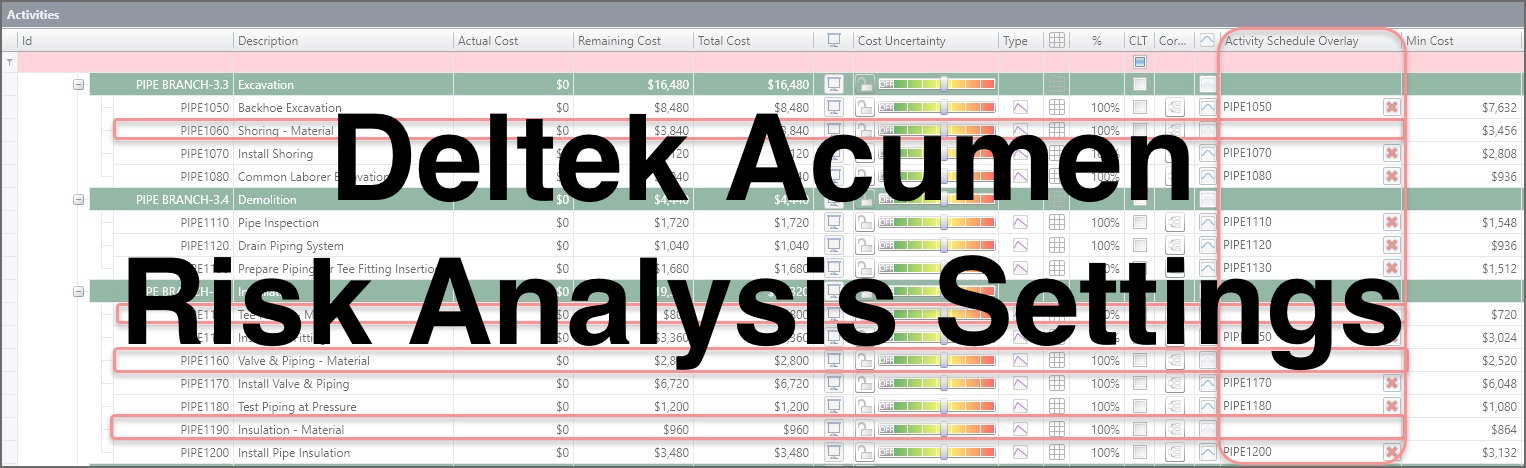
This setting is helpful for labor and equipment costs that tend to increase as the schedule lengthens. Material expenses, however, are not affected by schedule extensions. Material costs are best modeled as separate activities in the schedule and then removed from the cost model’s schedule overlay. In Figure 19, we have an underground pipe schedule, where all the material activities have been excluded from the ‘activity schedule overlay’ column.
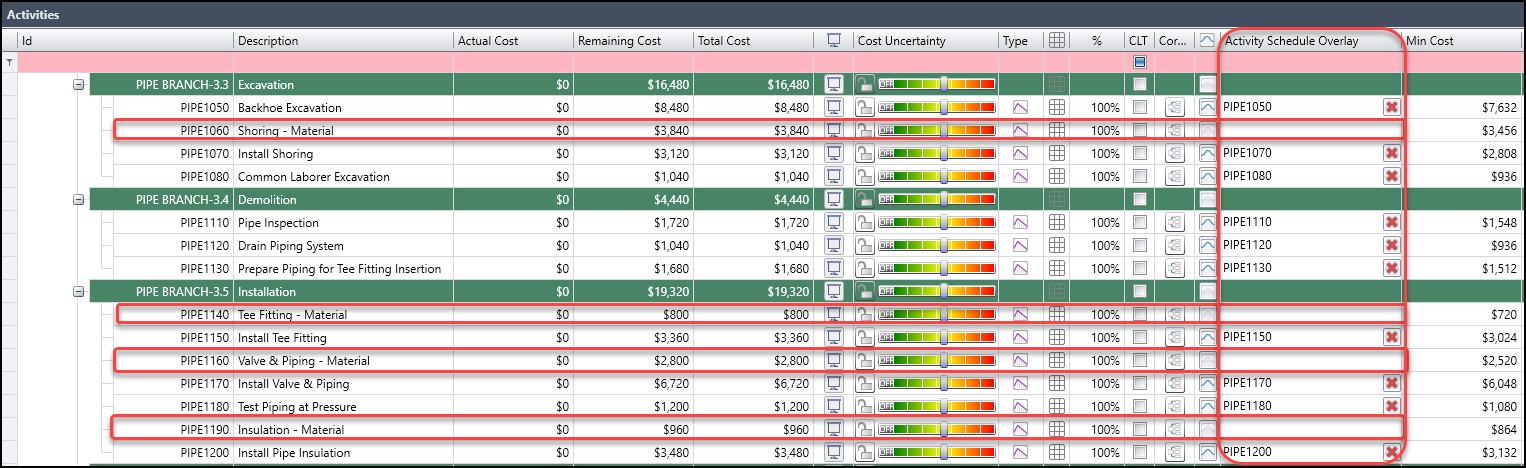 Figure 19
Figure 19
Summary
Again, the default Deltek Acumen Risk analysis settings may be a good place to start for those that are new to Acumen’s Monte Carlo risk analysis. But understanding the backdrop behind the Acumen Risk analysis settings, provides the scheduler a better understanding and more confidence in the accuracy and relevance of risk analysis results. This is important because the Deltek Acumen Risk results are all about creating confidence levels and ranges into which our schedule is most likely to fall.